在近日由量子位主办的MEET2025智能未来大会上,声网的COO刘斌发表了精彩的主题演讲,深入探讨了实时多模态趋势下,RTE(实时互动引擎)如何推动AI Agent应用的落地,并展望了其在生成式AI时代中的基础设施角色。
刘斌首先提及了两个重要事件:今年10月,声网的关联公司Agora作为语音API合作伙伴,出现在OpenAI发布的Realtime API公开测试版中;而在同月的RTE2024实时互联网大会上,声网宣布正与MiniMax共同研发国内首个Realtime API。这两个事件标志着大模型交互正快速向实时多模态发展。

刘斌指出,多模态模型的推出,改变了传统的纯文本交互方式,实现了从异步到实时双工交互的飞跃。然而,在实际应用中,用户设备往往无法保持在固定的网络与物理环境下,这对大模型实时语音对话中的低延时传输、网络优化等提出了挑战。模型交互中的智能打断和主动交互能力也是用户关心的重点,这要求不仅有强大的模型能力,还需要端到端的技术支持。
作为全球实时互动云行业的开创者,声网凭借在音视频领域的深厚积累,将RTE与生成式AI相结合,推出了声网Conversational AI Agents,旨在帮助开发者和企业快速构建适配自身业务场景的AI实时语音对话服务。通过自研的SD-RTN™实时传输网络,声网实现了全球范围内的低延时音视频传输,语音对话延迟低至500ms,并通过一系列技术手段保证了对话的实时性和流畅性。
在支持智能打断方面,声网自研的AI VAD技术能够适应人类对话的停顿、语气和节奏,支持对话过程中的随时打断。同时,声网的解决方案还优化了AI角色,保留了情绪情感等关键信息,提供了超拟人的真实音色,丰富了通话体验。
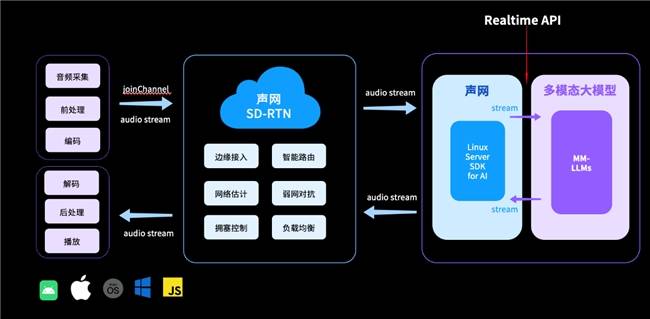
声网的音视频SDK经过不断迭代升级,能够支持30多个平台框架、30000多种终端机型及各种操作系统,包括各类IoT设备终端。在音频处理方面,声网具备业界领先的音频3A能力,提供AI回声消除、AI智能降噪等自研音频技术,确保在嘈杂环境中AI对话不受影响。
在与大模型厂商的合作中,声网发现现有RTE技术栈和基础设施仍有改进空间。刘斌表示,只有不断演进,大模型才能在各种场景和形态下大规模参与人的语音对话,并基于云、设备端、边缘等多维度进行参与和协作。基于这些能力的改进和普及,未来RTE将成为生成式AI时代AI基础设施的关键部分。
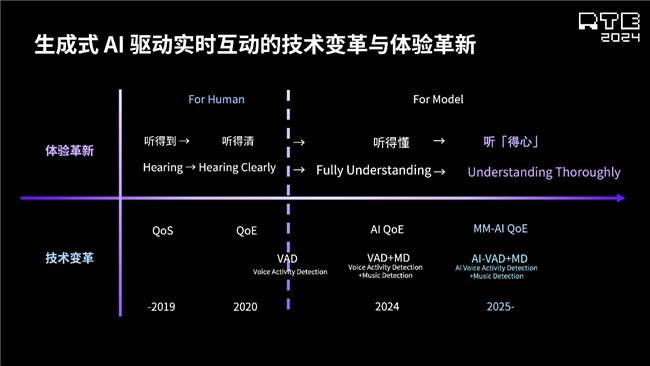
刘斌还介绍了声网的AI RTE产品矩阵,包括Linux Server SDK、AI VAD能力、AI Agent Service等,都在进行补充与优化。他展示了声网的RTE+AI能力全景图,包括RTE+AI生态能力、声网AI Agent、Conversational AI Agents解决方案等,全面展现了声网对RTE+AI的整体思考和布局。






















