在AI领域,一位新星正以独特的姿态崛起,他就是DeepSeek的创始人梁文锋。与众多科技巨头的大手笔投入不同,梁文锋和他的团队正走在一条截然不同的道路上,却同样收获了令人瞩目的成果。
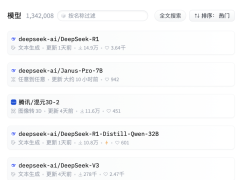
近日,DeepSeek发布了新一代多模态大模型Janus-Pro,该模型分为70亿参数和15亿参数两个版本,并且全部开源。这一消息迅速在AI界引起了轰动,Janus-Pro一经发布便登上了知名AI开源社区Hugging Face的模型热门榜,甚至在前五名中占据了四席之地。
据DeepSeek介绍,相比去年11月发布的JanusFlow,Janus-Pro在训练策略上进行了优化,扩展了训练数据,模型规模也更大。在多模态理解和文本到图像的指令跟踪功能方面,Janus-Pro取得了重大进步,同时增强了文本到图像生成的稳定性。这一系列的改进使得Janus-Pro在多项基准测试中表现出色,甚至在某些方面超越了OpenAI的DALL-E 3和Stable Diffusion。
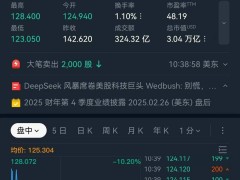
值得注意的是,DeepSeek的“小力出奇迹”策略再次得到了验证。与众多投入巨资打造大模型的科技公司不同,DeepSeek以较小的参数量和较低的成本实现了令人惊艳的效果。这种策略不仅体现在Janus-Pro上,早在本月早些时候发布的R1大模型上就已经初露锋芒。R1在数学、代码、自然语言推理等任务上的性能号称可以比肩OpenAI的o1模型正式版,但DeepSeek所花费的资金和资源却远远低于OpenAI。
DeepSeek的这种策略对AI行业的传统思维构成了挑战。长期以来,许多科技公司都信奉“大力出奇迹”的理念,认为只有投入巨资和资源才能取得突破。然而,DeepSeek的成功证明,在技术创新的加持下,“小力”同样可以创造“奇迹”。这一发现不仅揭示了一条新的技术路线,也蕴含着新的商业哲学。
在Janus-Pro发布之前,R1大模型已经让科技界为之惊叹。而Janus-Pro的发布更是进一步巩固了DeepSeek在AI领域的地位。据DeepSeek披露的信息,Janus-Pro的训练成本相对较低,使用轻量级的分布式训练框架,1.5亿参数模型大约需要使用128张英伟达A100芯片训练7天,70亿参数模型则需要256张A100芯片和14天训练时间。这样的成本在大模型训练成本动辄以亿为单位的大环境中显得尤为突出。
除了成本上的优势外,Janus-Pro在性能上也表现出色。它采用自回归框架,将多模态理解和生成统一起来,通过解耦视觉编码来增强框架的灵活性。这种设计使得Janus-Pro在多模态理解和生成方面取得了显著进步。在实际应用中,无论是文生图还是图生文任务,Janus-Pro都能生成高质量的结果。

DeepSeek的开源策略也为其赢得了广泛的关注和赞誉。Janus-Pro使用MIT协议进行开源,使得个人和中小企业能够以较低的成本使用这一先进的大模型。由于模型体量相对较小,Janus-Pro还可以在PC端安装、本地运行,进一步降低了使用成本。
DeepSeek的成功对AI行业产生了深远的影响。它不仅打破了传统的大模型训练成本高昂的固有印象,还展示了技术创新在推动AI发展方面的重要作用。与此同时,DeepSeek的开源策略也为AI技术的普及和应用提供了有力的支持。
然而,DeepSeek的成功并非没有挑战。在AI领域,许多科技公司仍然坚持“大力出奇迹”的策略,投入巨资和资源进行研发。随着AI技术的不断发展,新的竞争者和挑战者也在不断涌现。因此,DeepSeek需要不断创新和进步,以保持其在AI领域的领先地位。

尽管如此,DeepSeek已经以其独特的策略和卓越的表现成为了AI领域的一股不可忽视的力量。它的成功不仅为AI技术的发展提供了新的思路和方法,也为整个行业的发展注入了新的活力和动力。