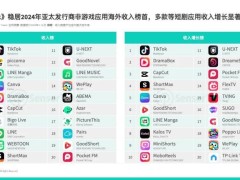
在农历新年之际,科技界的焦点并未因节日氛围而黯淡,反而因一家杭州“小公司”DeepSeek的崛起而更加炽热。DeepSeek以其创新的AI技术,为整个行业带来了新的活力和思考。
自DeepSeek-V3模型去年年底发布以来,其性能便备受瞩目。该模型在多项评测中超越了Qwen2.5-72B和Llama-3.1-405B等开源模型,与闭源模型GPT-4o和Claude-3.5-Sonnet不相上下。这一成就迅速吸引了业内人士的广泛关注,但DeepSeek的真正“出圈”还要等到其手机应用上线前夕。
1月20日,DeepSeek再次发力,推出了推理模型DeepSeek-R1。该模型在性能上实现了对OpenAI-o1正式版的对标,并且DeepSeek大方地公开了DeepSeek-R1的训练技术,同时开源了模型权重。对普通用户而言,DeepSeek-R1更是直接在官网上免费开放使用,这一举措无疑为AI技术的普及和应用注入了新的动力。
DeepSeek-R1不仅性能卓越,而且使用灵活。它支持联网搜索信息,增加了使用的便捷性。同时,作为一款采用CoT思维链技术的推理模型,DeepSeek-R1能够向用户展示其思考过程,让用户直观感受到大模型技术的实力。这一特点在海内外全网引发了热烈讨论,DeepSeek也因此承受了巨大的访问压力和恶意攻击。

DeepSeek的成功并非偶然。其两大核心技术——MoE混合专家模型和RL强化学习,为其带来了显著的成本优势和性能提升。MoE架构通过将一个复杂问题分解成多个更小、更易于管理的子问题,并由不同的专家网络分别处理,从而大大降低了推理成本。而RL强化学习则完全依赖环境反馈来优化模型行为,使模型在训练中自主发展出自我验证、反思推理等复杂行为,达到ChatGPT o1级别的能力。
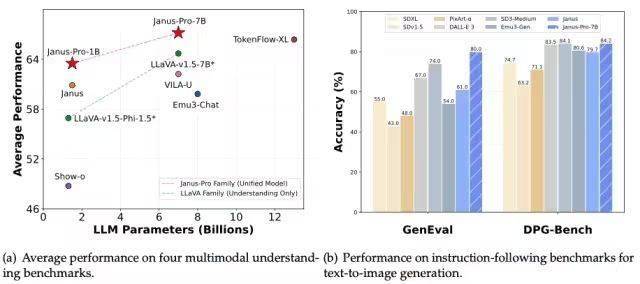
尽管DeepSeek-V3和DeepSeek-R1已经足够强大,但他们仍然只是“大语言模型”,不具备多模态能力。然而,DeepSeek并未止步于此。1月28日凌晨,DeepSeek开源了全新的视觉多模态模型Janus-Pro-7B。该模型通过将视觉编码过程拆分为多个独立的路径,解决了以往框架中的局限性,同时仍采用单一的统一变换器架构进行处理。这一创新使Janus-Pro在Geneval和DPG-Bench基准测试中击败了Stable Diffusion和OpenAI的DALL-E 3。

DeepSeek的崛起引起了AI大模型领域其他公司的关注。在DeepSeek-R1发布后不久,阿里通义团队便推出了Qwen2.5-Max模型。该模型使用超过20万亿token的预训练数据及精心设计的后训练方案进行训练,性能表现与业界领先的模型相当。Qwen2.5-Max的发布不仅展示了阿里在AI技术上的实力,也反映了DeepSeek对行业的影响力和推动力。
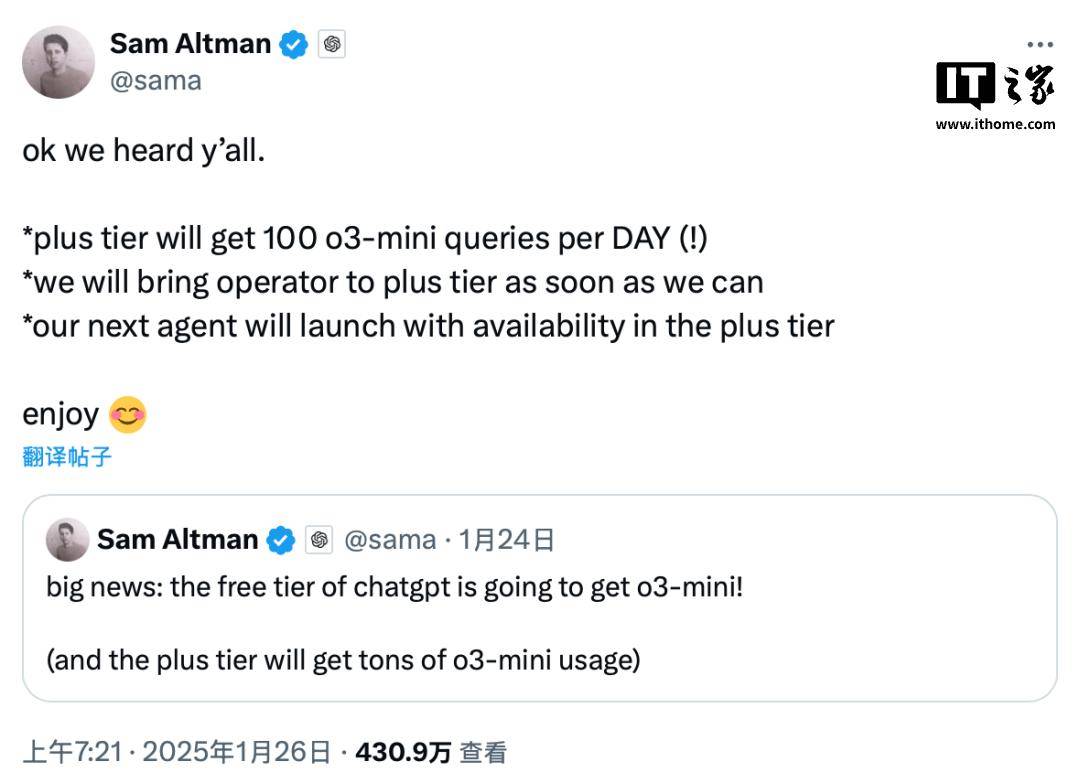
面对DeepSeek等竞争对手的压力,OpenAI的CEO阿尔特曼也表示将采取一系列措施来优化成本和提升用户体验。他透露,未来的ChatGPT o3-mini模型将开放给免费用户使用,Plus会员则每天有100条请求的额度。同时,新的ChatGPT Operator功能也将尽快向Plus会员开放。