近期,人工智能领域的一则新闻激起了广泛讨论。据透露,斯坦福大学与华盛顿大学的科研团队,在李飞飞的带领下,仅凭不到50美元的云计算成本,就成功研发出了一款名为s1的人工智能推理模型。该模型在数学与编程能力测试中的成绩,据传与OpenAI的O1和DeepSeek的R1等尖端推理模型不相上下。
这一消息在AI界犹如一颗震撼弹,引发了诸多疑问与好奇。为了探究真相,《科创板日报》记者深入调查并采访了多位业内人士。调查结果显示,s1模型的训练并非完全从零开始,而是基于阿里云的通义千问(Qwen)模型进行了监督微调。这意味着,s1模型之所以能以如此低的成本实现卓越性能,是因为它站在了一个已经具备强大能力的开源基础模型之上。
根据李飞飞团队的研究论文,s1模型的训练仅使用了1000个样本数据。在AI训练领域,这一数据量可以说是微不足道,通常不足以训练出一个具备推理能力的模型。上海交通大学人工智能学院的谢伟迪副教授表示,仔细研读斯坦福s1的论文后不难发现,s1模型的神奇之处在于它是以通义千问模型为基座进行微调,那1000个样本数据更像是对整体性能的一种“润色”,而非模型训练的全部。
国内一家知名大模型公司的CEO也向《科创板日报》记者透露:“从论文原文来看,所谓用50美元训练出具有推理能力的新模型,实际上只是用从谷歌模型中提炼的1000个样本对通义千问模型进行了监督微调。这种微调的成本确实很低,但明显是站在了既有领先模型的肩膀上。”

斯坦福s1论文原文中明确注明,模型是以阿里通义千问模型为基础进行了微调。谢伟迪指出,国内外还有其他团队也声称以极低的成本训练出了具备推理能力的新模型,但深入阅读其论文原文后,会发现它们都是基于通义模型作为基座进行的。
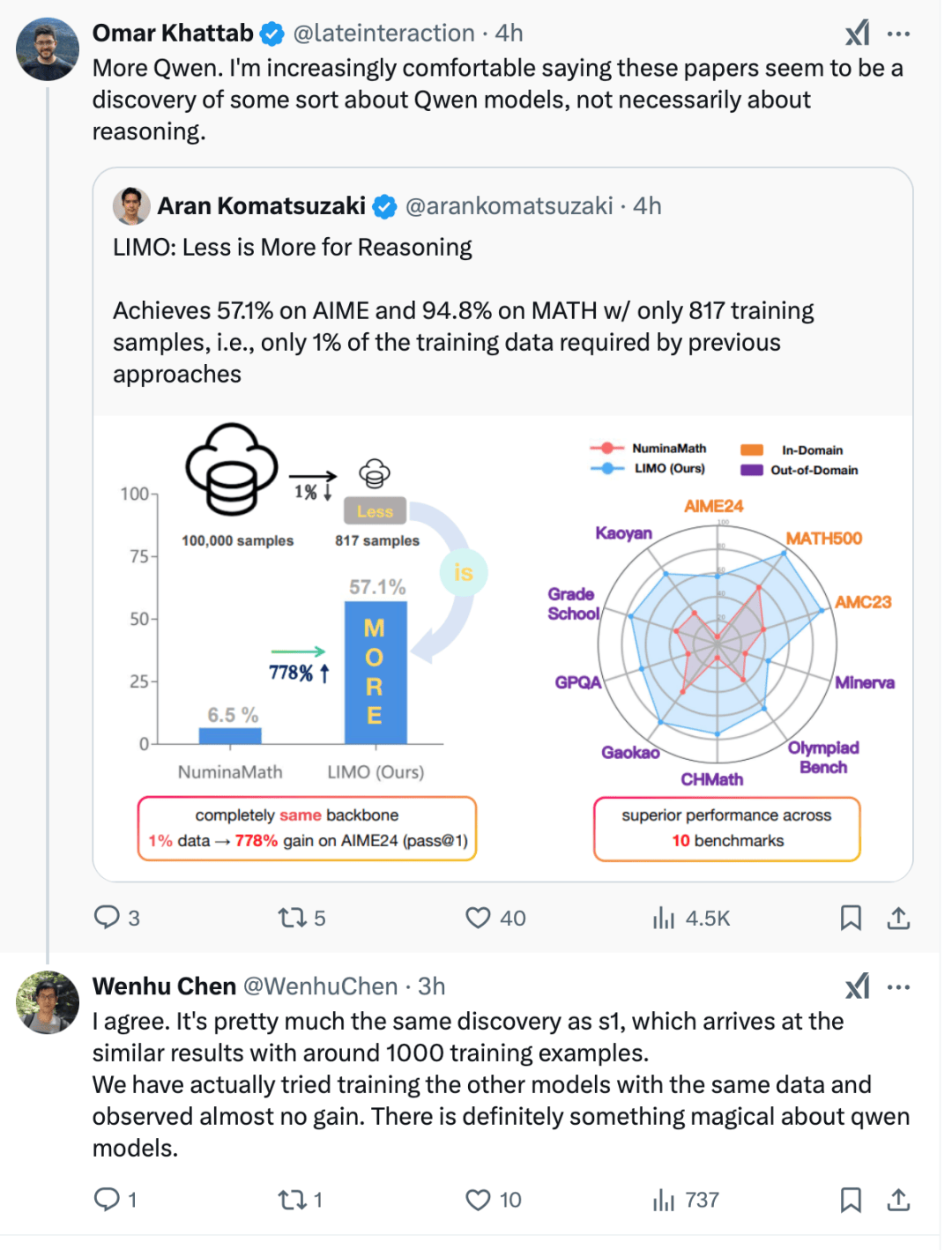
国外多位人工智能研究者也指出,许多所谓的“新”模型实际上都是建立在通义模型的基础之上的。谢伟迪强调:“以通义千问模型作为基座,确实可以用很少的样本数据就达到产生新的推理模型的效果,但如果换成其他基座模型,新模型的能力却不会有任何提升。所以,真正神奇的是Qwen模型,而不是s1。”
尽管s1模型的低成本训练在一定程度上展示了AI训练的潜力,但其局限性同样不容忽视。首先,这种低成本训练方法依赖于已有的强大基座模型,如阿里通义千问模型。如果没有这样的基座模型,低成本训练的效果将大打折扣。其次,1000个样本数据的训练量在大多数情况下是远远不够的,尤其是在处理复杂任务时。低成本训练的成功也引发了关于AI模型知识产权和伦理问题的广泛讨论。
如果越来越多的研究依赖于已有的基座模型进行微调,那么这些基座模型的开发者是否应该获得相应的回报?如何确保AI技术的公平使用和共享?这些问题都需要业界进行深入探讨和解决。尽管s1模型的低成本训练方法引发了诸多争议,但其背后的研究思路无疑为AI领域带来了新的启示和思考。