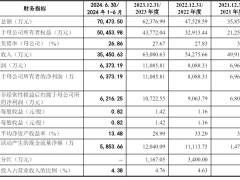
在AI领域的激烈竞争中,一个引人注目的转折点出现了:腾讯,这家科技巨头,近期宣布在其AI助手腾讯元宝中接入了DeepSeek-R1模型,使用户能够在腾讯混元大模型和DeepSeek-R1之间自由切换。此举标志着腾讯成为首家将DeepSeek集成到自家主力产品中的大厂,打破了此前仅在云服务平台上提供DeepSeek模型供外部开发者使用的常规。
对于这一决策,业内分析人士指出,对于拥有自研大模型的科技大厂而言,是否接入DeepSeek是一个棘手的选择。尤其是在自家AI助手上直接接入,无异于间接承认DeepSeek-R1的表现优于自家模型。然而,腾讯内部人士透露,接入DeepSeek更多是出于能力互补的考虑,并强调腾讯在大模型自研的道路上仍将坚定前行。
腾讯的这一举动,与其在AI领域相对稳健的发展步伐形成鲜明对比。在过去两年的大模型竞赛中,无论是自研大模型的上线时间还是AI助手的发布节奏,腾讯都显得相对从容不迫。这种“慢半拍”的策略,在某种程度上成为了腾讯敢于率先接入DeepSeek的“优势”。
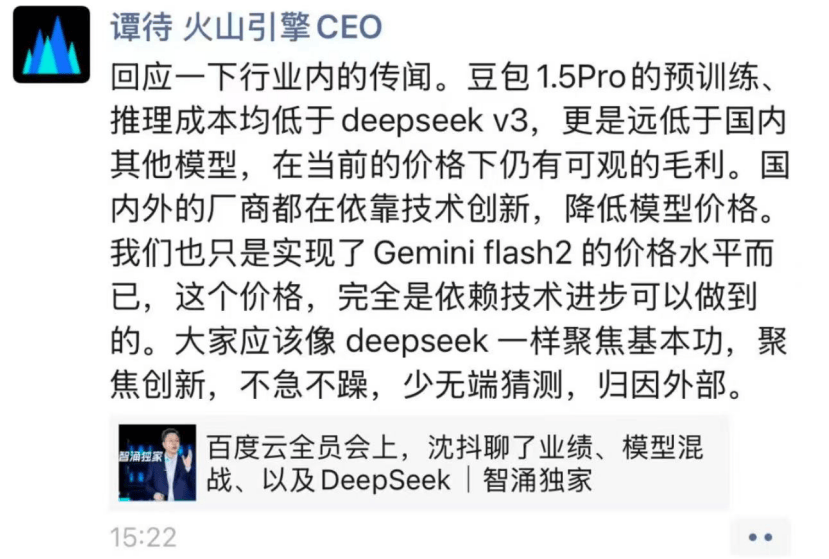
与此同时,另一家科技大厂字节跳动的AI助手豆包,在过去一年中迅速崛起,成为中国月活用户数最多的AI对话应用。然而,面对DeepSeek的异军突起,豆包也面临着前所未有的挑战。百度智能云事业群总裁沈抖在内部会议上指出,DeepSeek的来势汹汹,首当其冲的便是字节的豆包,其训练成本和投流成本高昂。尽管字节方面对此进行了反驳,强调豆包1.5 Pro的预训练和推理成本均低于DeepSeek V3,但不可否认的是,DeepSeek的“神秘东方力量”已经掩盖了豆包的光芒。
数据最能说明问题。根据QuestMobile的数据,DeepSeek的日活跃用户(DAU)在短短20天内从首次超越豆包的1695万增长到突破3000万大关,成为国内DAU最高的AI对话产品。OpenAI CEO奥特曼认为,DeepSeek所展示出来的思维链、免费且大规模可用等特性,激发了人们的体验热情。
面对DeepSeek的强劲势头,字节并未透露出在豆包中接入DeepSeek的迹象。相反,字节CEO梁汝波在全员会上表示,将继续加强规模效应,做大豆包用户群,并追求AI技术研发和创新。然而,对于2025年的重点目标,梁汝波也承认,DeepSeek的技术能力令人印象深刻,字节需要更快地跟进技术变化。
腾讯和字节的不同策略,反映了科技大厂在AI领域的不同选择和考量。腾讯的“慢半拍”策略,使其在接入DeepSeek时显得更为从容;而字节则在奋起直追的过程中,面临着如何在保持自研优势的同时,应对DeepSeek带来的挑战。
DeepSeek的崛起,不仅改变了科技大厂之间的竞争格局,也推动了AI需求的激增。业界普遍认为,C端AI应用有望在2025年爆发。为了普及AI应用,大模型厂商纷纷降价跟进DeepSeek的策略。然而,降价后的调用成本仍然高昂,直到DeepSeek R1模型的出现,才初步改变了这一局面。DeepSeek R1不仅运行成本比OpenAI o1便宜近30倍,还保持了高可靠性。
在错失与苹果AI的合作机会后,腾讯率先接入DeepSeek的举动,成为了其争取C端用户的Plan B。而字节则在张一鸣“大力出奇迹”的方法论指导下,通过全面自研和内部竞争的策略,使字节AI开始展现出后来居上的势头。阿里则在大模型发布上抢占先机后,开始调整策略加码“AI to C”。
然而,随着字节、阿里纷纷重注自家AI助手,它们在接入第三方大模型上变得更加纠结和有压力。一旦选择在自家核心AI应用上接入DeepSeek,可能会引发内部资源分配权的争夺战,以及用户忠诚度的考验。

为了应对DeepSeek带来的冲击,部分大模型头部玩家开始改变竞争策略。OpenAI官宣了GPT-5的消息,百度也传出了文心5.0即将面世的计划。两家都希望通过新模型的发布增强外界对自身技术体验的信任度,并一改过去的收费、闭源策略,向用户免费开放新模型。
DeepSeek带来的压力并未改变大模型厂商对算力需求的追逐。科技大厂依然坚信缩放定律(Scaling Laws),这也在一定程度上解释了英伟达股价的起伏变化。然而,对大模型厂商的价值重估仍在继续,融资环境变得更为谨慎。想要在大模型领域重获用户青睐,唯一的捷径便是通过技术创新证明自己。