近日,智元机器人在科技领域迈出重要一步,正式推出了其首个通用具身基座模型——智元启元大模型(Genie Operator-1)。这一创新成果标志着机器人在理解环境、执行任务方面取得了显著进展。
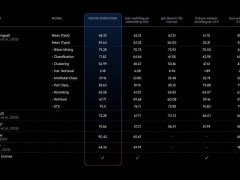
智元启元大模型的核心在于其独特的Vision-Language-Latent-Action (ViLLA) 架构。该架构由两大组件构成:VLM(多模态大模型)和MoE(混合专家)。VLM组件通过分析海量的互联网图文数据,赋予了模型在通用场景中的感知和语言理解能力。这意味着机器人能够更准确地识别环境、理解人类语言,从而做出更加智能的反应。
MoE组件则进一步增强了机器人的动作理解和执行能力。其中,Latent Planner(隐式规划器)通过分析大量的跨本体和人类操作视频数据,让机器人获得了在复杂环境中规划行动的能力。而Action Expert(动作专家)则通过百万真机数据的训练,使机器人具备了精细、准确的动作执行能力。这两者的结合,使得机器人能够在面对不同任务时,快速做出反应并高效执行。
智元启元大模型的这一创新架构,实现了利用人类视频进行学习的功能。通过这一功能,机器人能够在小样本情况下快速泛化,适应各种新的环境和任务。这一突破极大地降低了具身智能的门槛,使得机器人能够更加广泛地应用于各种实际场景中。
据悉,智元启元大模型已经成功部署到智元的多款机器人本体上。这些机器人将在未来在各个领域发挥更大的作用,为人类的生活和工作带来更多的便利和效率。这一成果的推出,也标志着智元机器人在推动人工智能技术发展方面迈出了坚实的一步。