近期,AI界迎来了一股新的浪潮,DeepSeek-R1的发布如同一颗石子投入平静的湖面,激起了层层涟漪。这款集成了尖端“思维链”技术的AI模型,在应对复杂任务时展现出了卓越的推理能力,并通过算法优化显著降低了本地部署的门槛。然而,其671B的庞大参数规模,对硬件的要求依然不容小觑。
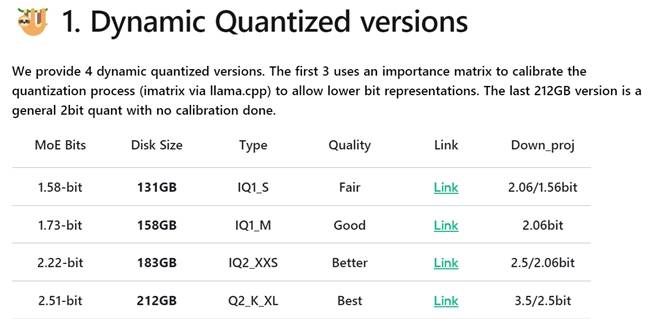
面对这一挑战,业界开始探索更为经济的部署方案。其中,动态量化技术脱颖而出,成为实现DeepSeek-R1低成本部署的关键。该技术通过对模型的关键层实施4到6bit的高精度量化,而对非关键的混合专家层(MoE)则采用更为激进的1到2bit量化,成功将DeepSeek-R1模型压缩至131GB,极大地降低了本地部署的成本。
为了进一步优化部署方案,此次采用了131GB大小的1.58-bit量化模型,并搭配云彣(UniWhen)「珑」系列DDR5 192GB套条作为显存替代方案。云彣(UniWhen)作为紫光国芯旗下的品牌,其「珑」系列DDR5 192GB套条专为大容量存储需求设计,单条容量高达48GB,不仅满足DeepSeek-R1的部署需求,更以高品质原厂颗粒和十层PCB堆叠设计,为AI运算提供强大支持。

在外观设计上,云彣(UniWhen)「珑」系列DDR5 192GB套条汲取了传统文化的灵感,以“龙”元素为主题,配合古代城楼的“飞檐翘角”,展现出华贵与庄严的气质。同时,提供云锦白与朱砂红两款色泽供用户选择,彰显个性品味。若追求RGB氛围,还可选择相同设计的「煌」系列,顶部覆有1600万色雾化导光条,并支持灯光同步功能。
实战部署方面,用户需先下载LM Studio,并通过其界面进行模型下载与配置。从Hugging Face网站下载unsloth DeepSeek-R1 GGUF 1.58-bit量化模型后,在LM Studio设置中选择CPU llama,并使用内存加载AI模型。经过测试,在上下文长度设定为20000且仅使用CPU运算的条件下,DeepSeek-R1 1.58-bit量化模型在云彣(UniWhen)「珑」系列DDR5 192GB套条的加持下,运算速度达到2.44 tok/sec,内存使用达到189GB,占用率为100%,足以满足日常任务中的流畅问答体验。
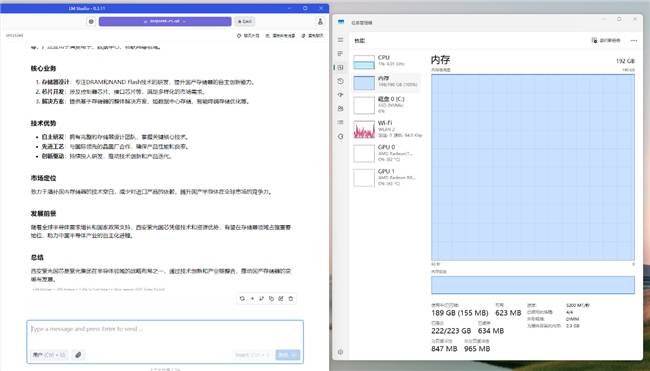
对于有长文本对话需求的用户,可选择非满血的70B蒸馏模型。在最大上下文长度达到131072的条件下,云彣(UniWhen)「珑」系列DDR5 192GB套条依然能够完整加载模型,并高效完成百万字数级别小说的数据处理任务。此时,内存使用降至90GB,占用率为47%,冗余充足。
面对AI算力硬件需求的不断增长,如何以更低成本进行本地化部署成为中小企业和个人用户的共同难题。云彣(UniWhen)「珑」系列DDR5 192GB套条不仅完美承载了满血DeepSeek-R1模型,带来更智能的AI体验,还凭借其卓越的材质和杰出性能,在高强度运算中确保了高效稳定。相较于传统显存方案,它无疑是预算有限用户的理想选择。