随着人工智能技术的蓬勃发展,尤其是生成式AI技术的日新月异,数据存储领域正经历着一场前所未有的变革。这一变革的核心,在于对存储性能要求的不断提升,以满足AI模型训练和推理过程中对数据处理速度和效率的高标准。
在AI模型的复杂度日益增加的背景下,存储系统面临着前所未有的挑战。多模态时代的到来,使得模型参数和计算复杂度呈现指数级增长,对存储带宽、容量和计算性能的需求也随之攀升。随着模型规模和训练精度的提高,Checkpoint的体积不断增大,对存储吞吐量的要求愈发严格。一旦存储性能无法匹配模型的复杂度,AI训练链条就会遭遇“存储瓶颈”,从而影响模型迭代的效率。
而在模型推理环节,更大的数据量、更复杂的模型以及更长的上下文窗口,虽然能够显著提升AI的效能,但也对存储系统提出了更高要求。推理过程需要应对大量并发请求,对响应时间有着极高的要求。同时,AI模型的频繁更新和快速部署需求也在不断增加,使得存储系统必须具备低延迟和高吞吐量的能力,以满足日益增长的应用需求。
与此同时,算力资源的紧缺问题也日益凸显。AI技术的发展推动了算力需求的急剧增长,GPU等算力资源供需矛盾突出。模型参数和复杂度的提升,使得模型训练所需的GPU算力不断增加,但目前的基础设施在算力资源的可用性和优化方面仍存在诸多挑战。频繁的Checkpoint数据写入和断点续训导致算力资源闲置,算力集群的利用率偏低,增加了训练时间和计算成本。
在这一背景下,存储性能的升级成为了提升GPU利用率的关键之一。通过提升数据加载效率、加快断点续训速度,可以显著减少训练过程中的等待时间,提升算力资源的使用效率。焱融科技作为国内专注于AI存储领域的领先存储解决方案提供商,针对这一需求,推出了搭载4张NVIDIA 400Gbps NDR InfiniBand网卡的存储方案。
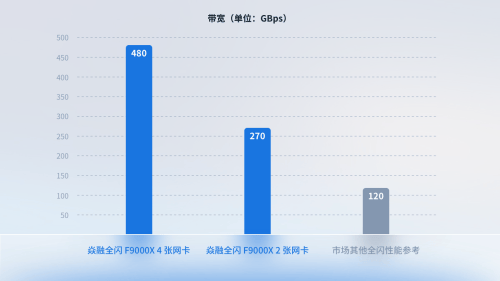
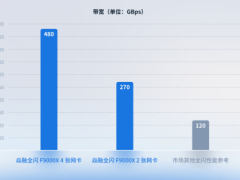
该方案依托于焱融追光全闪存储一体机F9000X,通过公司自主研发的Multi-Channel多网卡聚合技术,提供1.6Tb/s网络带宽接入能力,完美适配PCIe 5.0 NVMe闪存,大幅提升数据访问速度和处理效率。实测数据显示,采用4张InfiniBand 400Gbps网卡的焱融全闪F9000X存储方案,3节点存储集群的带宽性能达到了480GBps,相较于2卡方案性能提升了近80%,相比市场同类产品性能提升3倍;同时,其IOPS性能也达到了750万,保持业界领先水平。
这一突破性方案不仅大幅提升了性能,还有效降低了企业的总拥有成本。据测算,每GB/s的成本减少了75%,每IOPS的成本降低了30%。这一成本优势使得企业在享受高性能存储带来的业务效率和竞争力提升的同时,还能够有效降低总体拥有成本,是大规模AI计算场景下的理想全闪存储解决方案。
焱融科技在AI高性能存储领域的领先地位再次得到了彰显。继在国际权威AI测评舞台MLPerf Storage中崭露头角后,焱融全闪F9000X再次实现性能飞跃,为行业树立了新的标杆。这一成就不仅得益于焱融科技在AI存储技术创新方面的深耕细作,更得益于其对AI技术发展趋势的敏锐洞察和精准把握。
随着AI技术的不断发展,焱融科技将继续致力于AI存储技术的创新,持续提供领先的AI存储产品,为AI大模型、智算中心、自动驾驶、生信分析、金融量化等领域提供更强大的数据存储基座,推动这些领域的持续发展和创新。同时,焱融科技也将积极应对未来可能出现的挑战,不断提升自身的技术实力和创新能力,为AI技术的进一步发展贡献力量。