近期,非营利组织“人工智能安全中心”(CAIS)携手数据标注与AI开发服务商Scale AI,共同推出了一项名为“人类终极考试”的基准测试。该测试旨在全面评估前沿AI系统的综合能力,其难度之高,引起了业界的广泛关注。
这一基准测试的内容丰富多样,涵盖了数学、人文学科、自然科学等多个领域的问题。为了确保测试的权威性和深度,问题由来自50个国家/地区的500多个机构的近1000名学科专家撰稿人提出。这些专家包括教授、研究人员和研究生学位持有者,他们的专业知识为测试提供了坚实的基础。

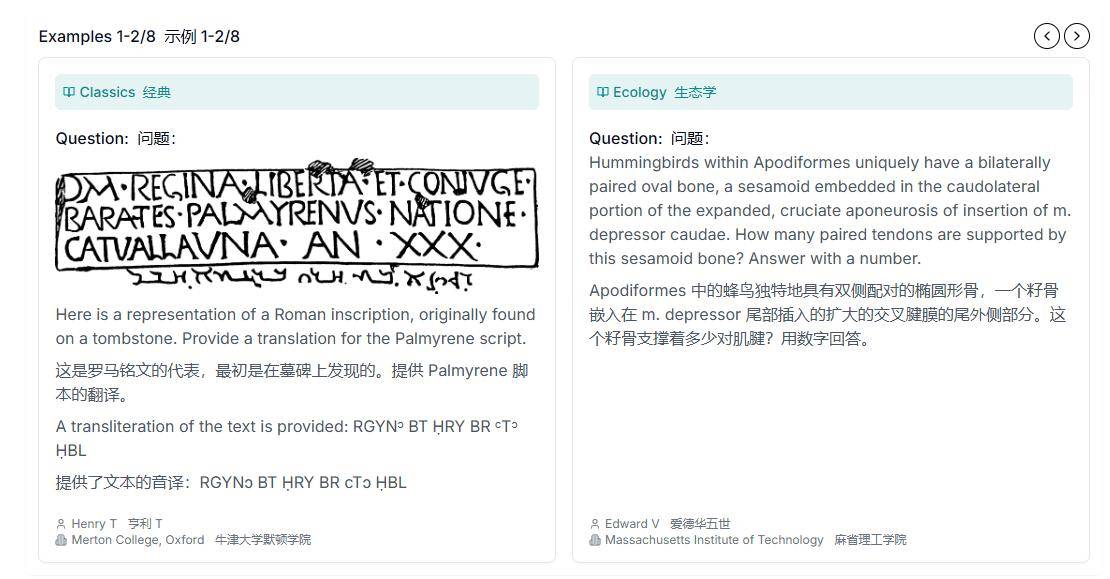
测试题目的设计也别具匠心,不仅包含了传统的文字题目,还结合了图表和图像等复杂题型。这种多模态的信息呈现方式,旨在全面考察AI系统在跨学科知识和多模态信息处理方面的能力。这样的测试设计,无疑对AI系统提出了更高的挑战。
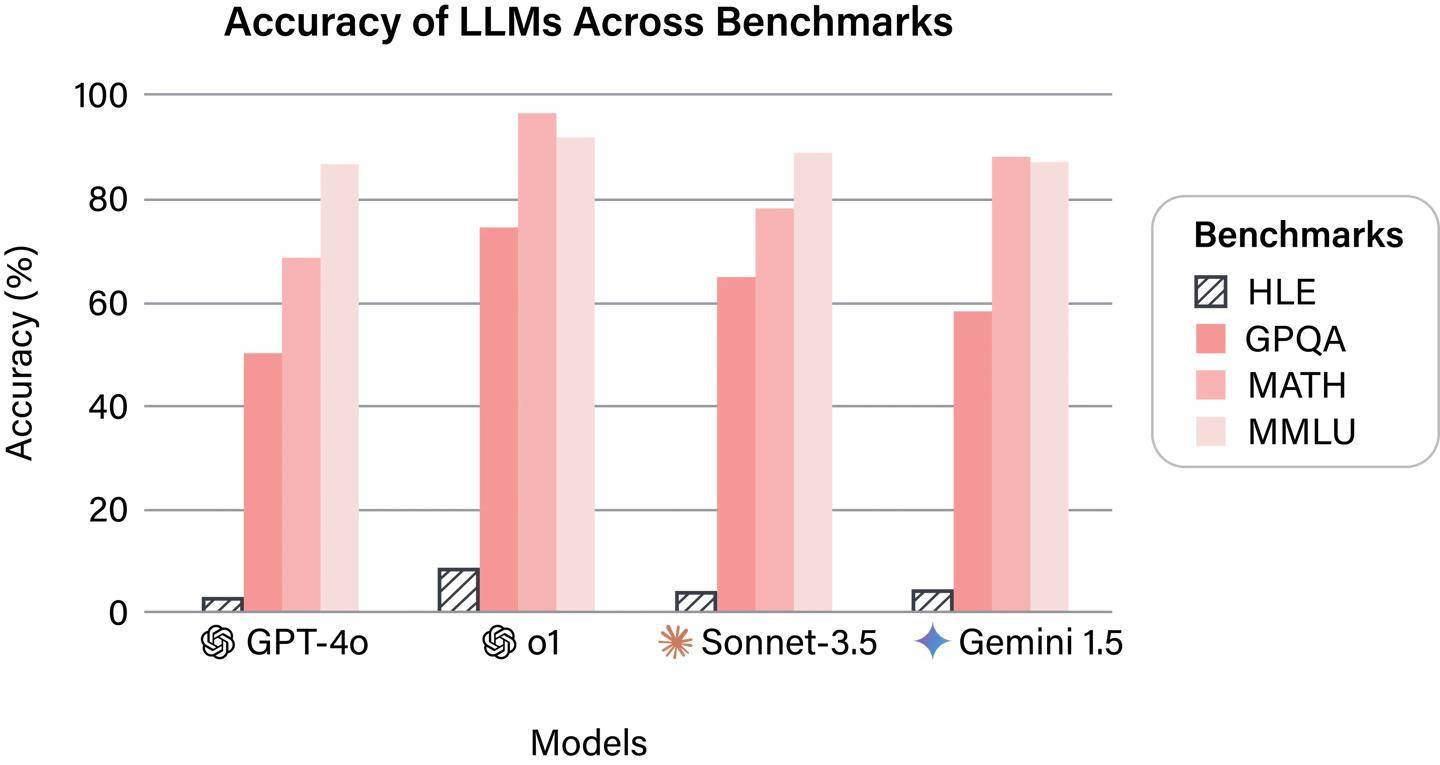
在初步的研究结果中,所有公开可用的旗舰AI系统在这一基准测试中的表现均不尽如人意。它们的回答准确率均未超过10%,这一结果揭示了当前AI技术在应对复杂、综合性问题时的明显短板。尽管AI技术在特定领域已经取得了显著的进展,但在面对跨学科、多模态的综合性问题时,仍然显得力不从心。
除了揭示AI技术的短板外,“人类终极考试”还为研究人员提供了一个宝贵的平台。CAIS和Scale AI计划将这一基准测试向研究社区开放,以便研究人员能够深入挖掘AI系统之间的差异,并评估新开发的AI模型。这将有助于推动AI技术的进一步发展,提高AI系统的综合能力。
该基准测试还展示了跨学科合作的重要性。来自不同领域的专家共同参与了测试题目的设计和评估工作,他们的专业知识和经验为测试的准确性和深度提供了有力保障。这种跨学科的合作方式,不仅有助于推动AI技术的发展,还能促进不同学科之间的交流和融合。