在2024年末的科技舞台上,智源研究院再度引领了一场关于人工智能大模型的深度评测盛宴。此次评测不仅覆盖了国内外100多个开源与商业闭源的语言、视觉语言、文生图、文生视频及语音语言大模型,还通过一系列综合及专项评测,全面揭示了当前大模型技术的最新进展与实际应用潜力。
相较于今年早些时候的评测,智源研究院此次在评测任务上进行了显著的扩展与深化。新增的数据处理、高级编程及工具调用能力评估,首次将金融量化交易场景纳入考量,并创新性地引入了基于模型辩论的对比评测方式,旨在更深入地剖析模型的逻辑推理、观点理解及语言表达等核心能力。
评测结果显示,2024年下半年,大模型的发展重心明显转向了综合能力的提升与实际应用。多模态模型异军突起,涌现出众多新厂商与新模型,而语言模型的发展则相对放缓。在开源生态中,除了持续坚定的开源倡导者,还出现了新的开源贡献力量。
在语言模型方面,尽管针对一般中文场景的开放式问答或生成任务已趋于稳定,但在复杂场景任务中,国内头部语言模型与国际一流水平仍存在明显差距。主观评测中,字节跳动Doubao-pro-32k-preview与百度ERNIE 4.0 Turbo分列前两位,而客观评测则由OpenAI的o1-mini-2024-09-12和Google的Gemini-1.5-pro-latest领跑。
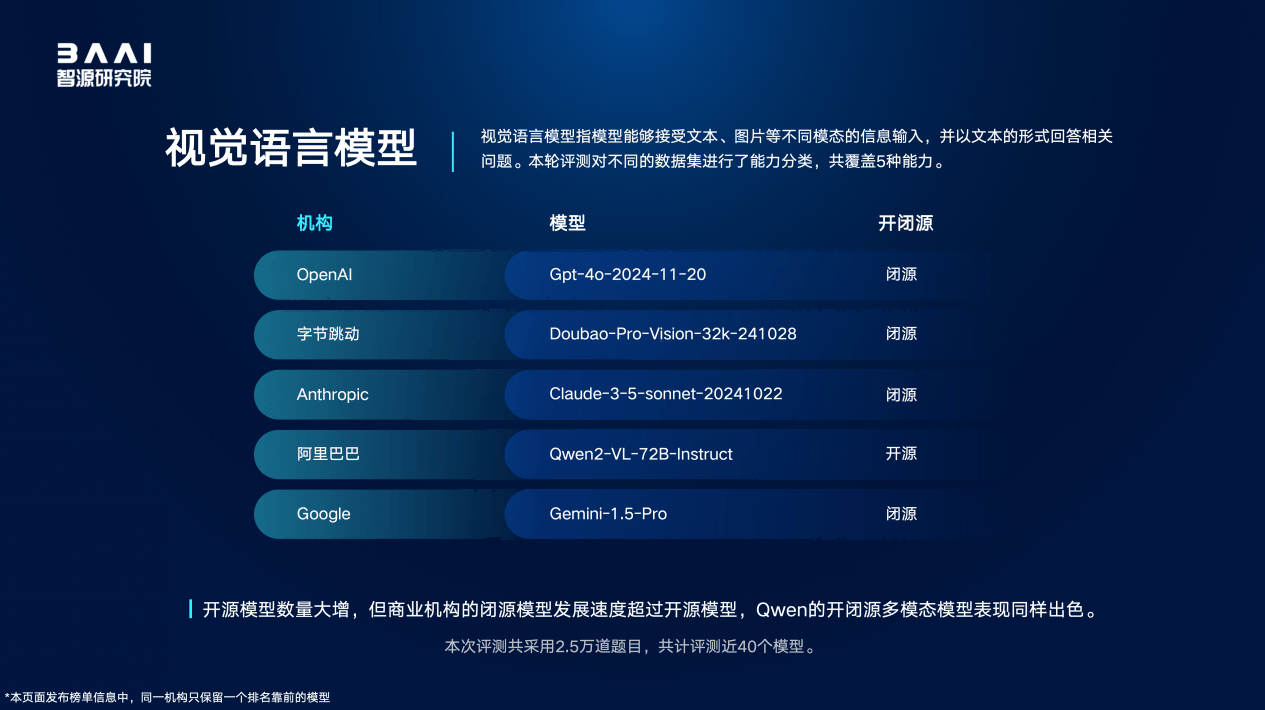
视觉语言多模态模型方面,尽管开源模型的架构趋于一致,但性能表现却大相径庭。较好的开源模型在图文理解任务上正逐步缩小与头部闭源模型的差距,但在长尾视觉知识与文字识别以及复杂图文数据分析方面仍有待提升。评测中,OpenAI GPT-4o-2024-11-20与字节跳动Doubao-Pro-Vision-32k-241028表现突出。
文生图多模态模型方面,头部模型已具备中文文字生成能力,但复杂场景人物变形仍是普遍问题。腾讯Hunyuan Image在评测中拔得头筹,字节跳动Doubao image v2.1与Ideogram 2.0紧随其后。
文生视频多模态模型则呈现出画质提升、动态性增强、镜头语言丰富的特点,但动作变形、物理规律理解不足等问题依旧存在。快手可灵1.5(高品质)、字节跳动即梦 P2.0 pro等模型在评测中表现优异。
语音语言模型得益于文本大模型的进步,能力提升显著,但开源模型中性能好、通用能力强的仍较少。阿里巴巴Qwen2-Audio在专项评测中位居榜首,香港中文大学与微软合作的WavLLM、清华大学与字节跳动合作的Salmon同样表现不俗。
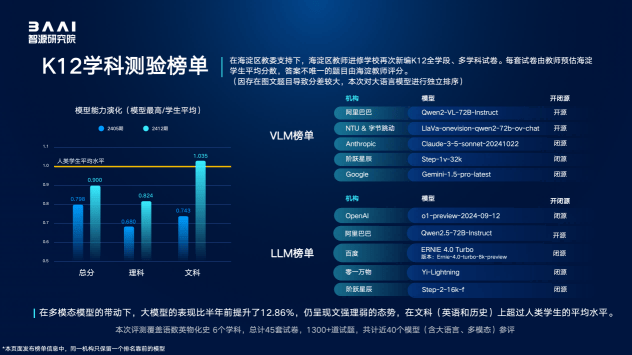
智源研究院还联合海淀区教师进修学校新编了K12全学段、多学科试卷,以考察大模型与人类学生的能力差异。结果显示,尽管模型在多模态能力的带动下综合得分有所提升,但仍与海淀学生平均水平存在差距,且普遍存在“文强理弱”的现象。
智源研究院此次评测还探索了基于实际应用场景的全新方法,通过评测模型的量化代码实现能力,探索其在金融量化交易领域的潜在应用。评测发现,头部模型已接近初级量化交易员的水平,深度求索Deepseek-chat、OpenAI GPT-4o-2024-08-06等模型在评测中表现突出。
作为评测体系的重要组成部分,智源研究院的Flageval平台经过数次迭代,已覆盖全球800多个开闭源模型,包含20多种任务、90多个评测数据集及超200万条评测题目。在评测方法与工具上,智源研究院联合多所高校和机构,探索了基于AI的辅助评测模型FlagJudge及灵活全面的多模态评测框架FlagevalMM,为评测提供了有力支持。






















