在科技界掀起波澜的DeepSeek,以其惊人的效率与低成本,推出了与OpenAI o1性能接近的开源模型R1,这一壮举被视作AI大模型领域的一次“小力出奇迹”。R1的成功不仅震撼了全球AI行业,也让外界开始质疑大型科技公司动辄数百亿美元的AI研发开支是否合理。
然而,尽管DeepSeek的冲击波让科技巨头们为之一震,但这些巨头并未因此改变策略。相反,他们正加大投入,试图通过资金优势重新夺回AI大模型的制高点。谷歌母公司Alphabet在2024年第四季度财报中宣布,2025财年的资本支出将达到750亿美元,以加速其人工智能战略的实施。这一数字远超华尔街的预期,彰显了谷歌在AI领域的烧钱决心。

微软也不甘落后,宣布将在2025财年投资800亿美元建设AI数据中心,创下公司成立以来单笔投资最高纪录。社交网络巨头meta同样计划在今年投资600亿至650亿美元,并大幅扩张AI团队,以实现其AI服务的宏伟目标。而OpenAI则携手软银、甲骨文、微软等企业,预计投资5000亿美元成立“星际之门”,用于AI基础设施的建设与运营。
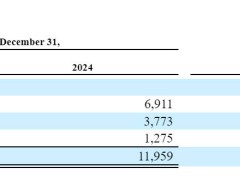
相比之下,国内科技巨头在AI大模型领域的投入虽然规模较小,但也动辄数百亿元,且增长迅速。百度、阿里、腾讯等企业在2024年前三季度的总资本开支约为867亿元人民币。金融数据服务商预计,到2027年,这三家企业的资本支出将达到1767亿元,年复合增长率超过26%。其中,很大一部分资金将流向AI大模型。
面对DeepSeek的崛起,美国科技巨头虽然在表面上对其技术赞叹不已,但在战略层面并未跟随其“小力出奇迹”的策略。相反,他们加大了在AI领域的投入。OpenAI在推出o3-mini模型后,展现了其在物理推理等多项指标上的强大实力,甚至在某些方面超越了R1。同时,OpenAI还发布了Deep Research功能,号称可以在短时间内完成人类专家数小时的工作。
尽管DeepSeek的R1模型取得了显著成就,但其在算力、数据、资金和资源方面仍无法与巨头们相提并论。DeepSeek正面临被后来者超越的风险,但其成功也证明了“小力出奇迹”的可行性。这一新范式让巨头们青睐的“砸钱”路线与“小力出奇迹”路线之争更加激烈。
在国内,字节跳动在AI大模型领域的投入同样引人注目。近年来,字节跳动洒下重金,不仅在研发费用和人才成本上大手笔投入,还在B端和C端同时烧钱,力图争夺更多企业和个人用户。其推出的豆包大模型在价格上堪称“价格屠夫”,同时依靠广泛的投放策略拉新,用户量迅速增长。

阿里云、百度智能云、腾讯云等国内主要云服务厂商也纷纷接入DeepSeek大模型,试图借助其流量为自己争取关注度和新用户。这一举动不仅表明了大厂对DeepSeek的认可,也为双方未来更大规模的合作留下了想象空间。
然而,随着竞争对手以新一代模型反击,叠加自身规模扩大导致的种种问题,DeepSeek正面临被全面反超的危险。其产品上的大模型幻觉问题频繁出现,让用户对其准确性产生质疑。同时,短时间内涌入的全球用户也让DeepSeek有些力不从心,其深度思考和联网搜索功能一度暂停服务。
尽管DeepSeek的“小力出奇迹”证明了AI大模型的另一条发展路径,但手握重金的科技巨头依然是AI大模型的主要参与者。他们坚守“尺度定律”,通过算力、算法和数据的三角模型构建更强大的模型。DeepSeek及其拥趸不能因一时的成功而沾沾自喜,高性价比路线与“大力出奇迹”路线之争仍将持续下去。