DeepSeek,这家中国的初创AI公司,正以惊人的效率革命颠覆着人工智能行业的成本结构,引发了全球范围内的广泛关注与讨论。
DeepSeek的开发成本极低,不仅开源而且服务完全免费,这一模式让众多AI从业者眼前一亮,甚至让世界首富马斯克都感到震惊。知名投资人“木头姐”凯茜·伍德更是直言不讳,称DeepSeek加剧了人工智能的成本崩溃。这股来自东方的神秘力量,不仅让世界为之侧目,更引发了中美AI领导地位更替的深思。
DeepSeek的颠覆性创新在于其极致的效率。据悉,DeepSeek仅用不到OpenAI十分之一的成本,就达到了后者最新大模型的性能。1月20日,DeepSeek正式发布了DeepSeek-R1模型系列,在Chatbot Arena大模型排行榜上,DeepSeek-R1的基准测试排名迅速攀升至全类别第三,与ChatGPT-4o最新版并驾齐驱,并在风格控制类模型分类中与OpenAI-o1并列榜首。这一成绩无疑是对DeepSeek效率的最佳证明。
据DeepSeekV3技术报告显示,V3模型的训练总计仅需要278.8万GPU小时,相当于在2048块H800(英伟达特供中国市场的低配版GPU)集群上训练约2个月,合计成本仅557.6万美金。而相比之下,GPT-4o模型的训练成本高达1亿美元,需要万块以上的H100 GPU。DeepSeek以不到十分之一的成本,达到了世界一流水平,这无疑是对传统“高投入、高算力”研发路径的一次重大挑战。
DeepSeek的成功,源于其自研的MLA和MOE架构,以及数据蒸馏技术的运用。通过一系列算法和策略,DeepSeek将原始复杂的数据进行去噪、降维、提炼,从而得到更为精炼、更有用的数据,极大提升了训练效率。这种“四两拨千斤”的能力,让DeepSeek在AI领域脱颖而出。
然而,DeepSeek的出现也引发了一些争议。OpenAI等科技大厂指责DeepSeek通过“模型蒸馏”技术“违规复制”其产品功能,但始终未提供具体证据。关于数据蒸馏技术的争议也在网络上持续发酵。但无论如何,DeepSeek已经以其颠覆性的成本优势,改变了人工智能产业的发展轨迹。
DeepSeek的颠覆性创新,不仅打破了摩尔定律和Scaling Law在AI行业的传统认知,更引领了AI创新进入追求效率、追求模型架构设计、工程优化的全新阶段。这一“范式转移”不仅破除了科技大厂建立的技术领先壁垒,还打破了重资本比拼的游戏惯例。DeepSeek的开源和免费模式,更是让全球AI行业为之震动。
面对DeepSeek的挑战,科技大厂们纷纷作出回应。OpenAI紧急上线新一代推理模型o3系列的mini版本,并首次免费向用户开放其基础功能。微软、谷歌、亚马逊、meta、苹果等巨头也加大了在AI领域的投入,期望通过“军备竞赛”维持自身在AI领域的全球领导地位。然而,DeepSeek的出现已经改变了超大规模扩张算力的行业发展“固定路径”,让科技大厂们的超级愿景面临挑战。
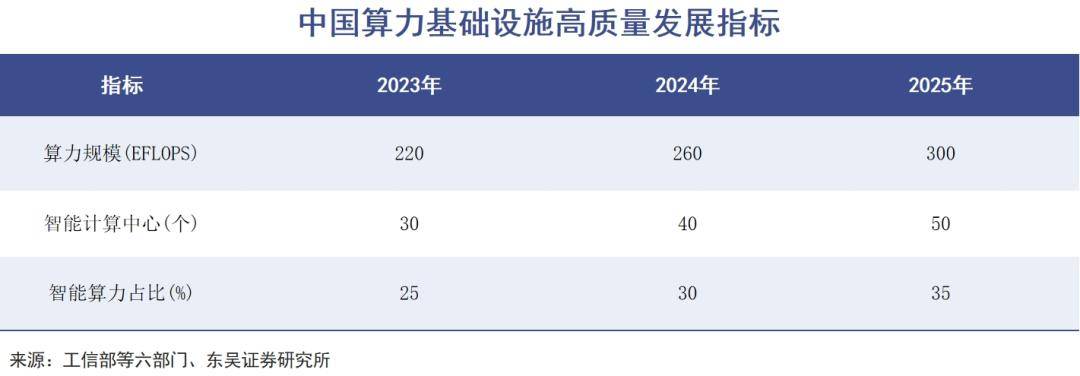
尽管如此,对于算力进行重新判断仍为时尚早。当前,我国算力部署占全球算力基础设施的26%,名列世界第二。在“算力即国力”的思潮下,东数西算等数字基础设施工程正积极进行。这些大规模部署和研发投入,都具有历史性的战略意义,是人工智能时代的重要社会财富。
DeepSeek的成功,不仅是中国AI行业的骄傲,更是中国智慧的体现。在资源匮乏的历史条件下,中国实现了工业现代化,而DeepSeek则以低成本开发出优质产品,再次展现了中国在创新领域的独特文化和韧性。中美AI的拉锯战中,DeepSeek的崛起无疑为中国企业赢得了一席之地,也让全球科技界重新审视中国AI的实力和潜力。