近期,科技巨头meta与顶尖学府斯坦福大学携手合作,推出了一款名为Apollo的全新AI模型系列,这一突破性的进展显著提升了机器对视频内容的理解能力。
尽管近年来人工智能在图像和文本处理领域取得了长足的进步,但让机器真正“看懂”视频内容依然是一项极为复杂的挑战。视频中所蕴含的动态信息丰富且多变,这对人工智能的处理能力提出了极高的要求,不仅需要强大的计算能力作为支撑,更需要在算法设计上实现创新。
为了应对这一挑战,Apollo模型采用了创新的双组件设计。其中一个组件专注于处理视频中的每一帧图像,而另一个组件则负责追踪对象和场景随时间的变化。这一设计使得Apollo能够更准确地捕捉视频中的动态信息,从而提升对视频内容的理解。
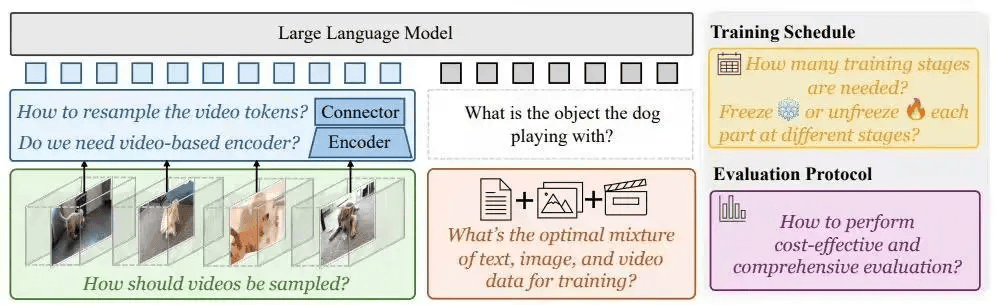
在模型训练方面,meta与斯坦福大学的研究团队也进行了深入的探索。他们发现,训练方法的选择对于模型性能的提升至关重要。因此,Apollo模型采用了分阶段训练的策略,通过按顺序激活模型的不同部分,实现了比一次性训练所有部分更好的效果。
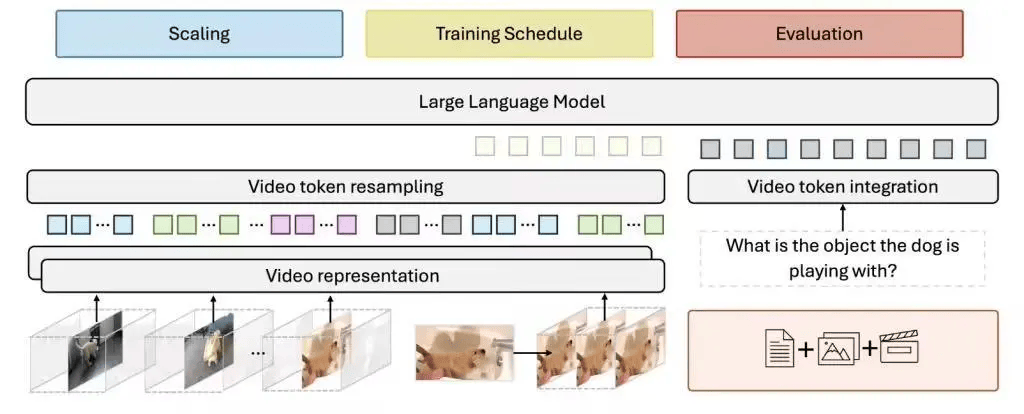
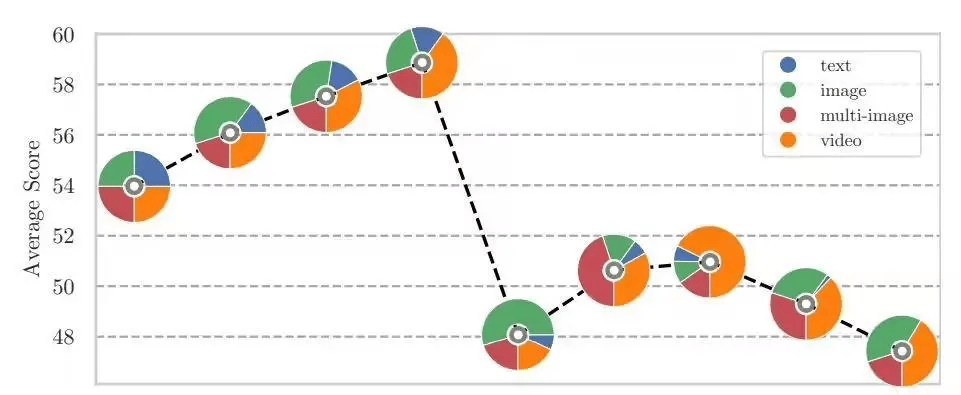
研究团队还优化了数据组合的比例,发现当文本数据占比在10%至14%之间,且其余部分略微偏向视频内容时,能够最好地平衡语言理解和视频处理能力。这一发现为Apollo模型在实际应用中的表现提供了有力的支持。
Apollo模型在不同规模上都展现出了出色的性能。其中,较小的Apollo-3B模型已经超越了同等规模的Qwen2-VL等模型,而更大的Apollo-7B模型则超过了参数更大的同类模型。这一卓越的表现使得Apollo模型在视频理解领域具有广泛的应用前景。
为了更好地推动Apollo模型的发展和应用,meta已经开源了Apollo的代码和模型权重,并在Hugging Face平台上提供了公开演示。这一举措将有助于更多的开发者和研究人员了解和使用Apollo模型,共同推动人工智能技术在视频理解领域的进步。






















