科大讯飞近日发布了其最新的投资者关系活动记录,详细阐述了DeepSeek和星火大模型X1的最新进展。记录显示,科大讯飞正在全力推进星火X1新版本的训练,这一版本预计将在3月内完成,目标是在数学答题和过程思维链能力上全面对标甚至超越OpenAI的o1模型。
科大讯飞强调,星火X1新版本的成功离不开其在深度推理模型上的深厚积累。通过与中国教科院等教育专家的紧密合作,科大讯飞正致力于将X1深度推理模型与教育专业知识相结合,通过强化学习和反思机制,生成符合教育教学需求的“教学思维链”。这一创新旨在提高复杂场景推理的逻辑正确性、专业性和可解释性,并计划率先应用于教师助手、作业批改和辅助教学等全系产品创新中,预计将在2025年世界数字教育大会上发布教育专属大模型和创新应用。
在DeepSeek方面,科大讯飞提到了R1版本的快速对标o1模型的创新点。R1采用了R1-Zero强化学习训练方案,直接在DeepSeek-V3-base预训练模型上进行大规模强化学习训练,无需依赖任何有监督微调(SFT),即可在数学、代码等推理任务上接近o1模型的效果。这一成果不仅减少了人工标注推理过程数据的需求,还体现了科大讯飞在深度推理模型上的技术创新能力。
值得注意的是,科大讯飞在深度推理模型上的进展并非一帆风顺。由于只能使用国产算力,科大讯飞在适配和优化华为昇腾910B算力上花费了额外的时间。然而,这些努力最终取得了显著成效,星火深度推理模型X1虽然参数较小(仅130亿),但依靠算法和数据优势,已达到与OpenAI o1-preview对标的水平。科大讯飞表示,随着国产算力的逐步到位和模型参数的增加,有信心实现数学答题和过程思维链能力的全面超越。
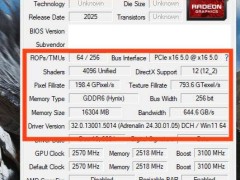
为了降低深度推理模型的训练和推理成本,科大讯飞在软硬件结合方面进行了多项深度工程优化创新。与DeepSeek直接在英伟达H800卡上开展工程优化不同,科大讯飞选择了更难的全国产算力路线。通过与华为的紧密合作,科大讯飞攻克了一系列技术难题,将训练效率从最初的30%-50%优化到了85%-95%以上。特别是在万卡网络通信带宽的利用率上,科大讯飞星火做到了95%,超越了DeepSeek的93%。
科大讯飞还指出,虽然陆续有公司宣布可以在国产算力平台上提供大模型的推理服务,但目前只有讯飞星火一家是训练和推理均在国产算力上进行的。仅用1万张910B国产算力卡,科大讯飞不仅取得了大模型研发上的显著成果,还做了大量国产算力平台上的适配和效率优化工作。这些努力体现了科大讯飞在追求国产算力极致效率上的技术实力和战略勇气。
科大讯飞表示,未来将继续加大在深度推理模型上的研发投入,推动星火大模型在教育、医疗等领域的广泛应用。同时,也将持续关注国产算力的发展动态,不断优化和提升星火大模型在国产算力平台上的性能和效率。